目前大数据及人工智能技术与油气开发业务正处于深度融合发展阶段,其强大的数据分析及学习能力让传统开发工作流程的转型升级具有了新的突破点。尤其是对类型多样、开发历史较长的油气田,在已积累了丰富的数据资源背景下,利用大数据及人工智能技术可实现开发经验的快速总结与应用。随着技术发展,国内外各大油气田在智能化建设上取得长足进步,油气田开发正处于从数字建设到智能化决策的重要转变阶段。传统的油气模拟主要以渗流力学、油层物理学为基础,研究油气开发过程中油、气、水的运移规律和驱替机理。当开发区块较大、开采条件较复杂时,需要使用大量网格块来捕获储层模型的综合信息(如孔隙度、渗透率、压力分布及饱和度分布等),大量的网格块与大量需要同时求解的质量平衡方程相关联,从而增加了求解这些方程所需的计算时间,带来巨大的计算代价。因此,随着深度学习技术的不断发展,代理模型作为油气智能化建设的核心,逐渐成为主要的研究方向之一。本文以tNavigator24.3版本为例,尝试初步构建基于LSTM(Long Short-Term Memory)网络的油藏代理模型,旨在初步探索深度学习在油藏模拟中的应用潜力。LSTM是一种特殊的递归神经网络(RNN),擅长处理和预测时间序列数据。由于油藏生产数据通常具有时间序列特性,LSTM网络在此类问题上表现出色。油藏模拟所涉及到的历史拟合、不确定性量化分析、开发方案优化等重要环节均需要大量数值模拟算例的支撑。以产量为井控去计算井底压力过程的单次算例可以表示为:
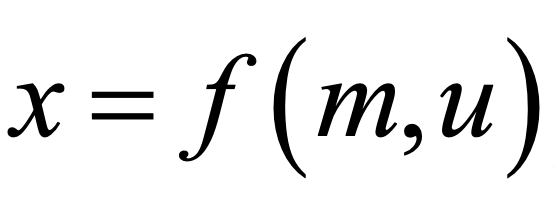
其中,f为油藏数值模拟过程,m为地质模型参数(渗透率),u为井控条件(井底流压),x为各个时间步计算的井底压力。深度学习方法的一个关键能力是同时从数据中检测有用的特征和近似输入到输出的映射。人工神经网络(ANN)作为深度学习的基础已广泛应用于代理模型,以实现油藏模拟的目的。基于深度学习方法,可将数值模拟算例近似表示为:
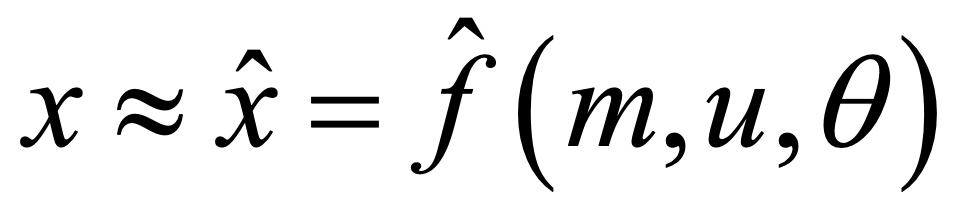
其中,为代理模型,为近似计算的井底压力,为深度学习的神经网络参数。如公式所示,构建代理模型的目的在于有效代替模拟器,能够基于地质模型参数在给定井控条件下,快速预测生产动态。由于存在梯度消失问题,基本RNN结构只能处理短期记忆,而存在长期依赖消失的问题。LSTM(长短期记忆网络)是一种特殊类型的循环神经网络(RNN),专门设计来解决传统 RNN 在处理长序列数据时遇到的梯度消失或梯度爆炸问题(多用来解决油气藏长时间的产量预测)。LSTM 通过其独特的 “门” 机制能够有效地学习长期依赖信息,使其在多种涉及序列数据的任务中表现优异,如自然语言处理、语音识别和时间序列预测等。LSTM 的关键在于其内部状态(cell state)和三个重要的门控机制:输入门、遗忘门和输出门。这些门控制着信息的流入、更新和流出,使 LSTM 能够在必要时保存信息跨越多个时间步,或者丢弃不再需要的信息。
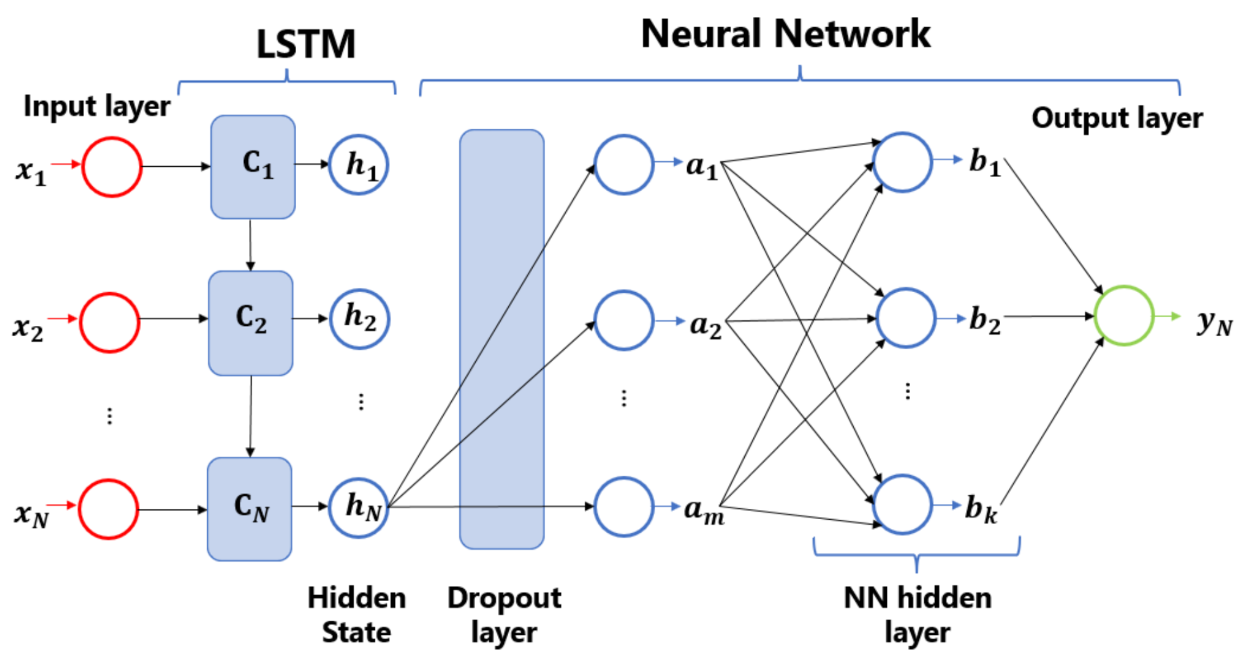
图1 LSTM网络内部结构
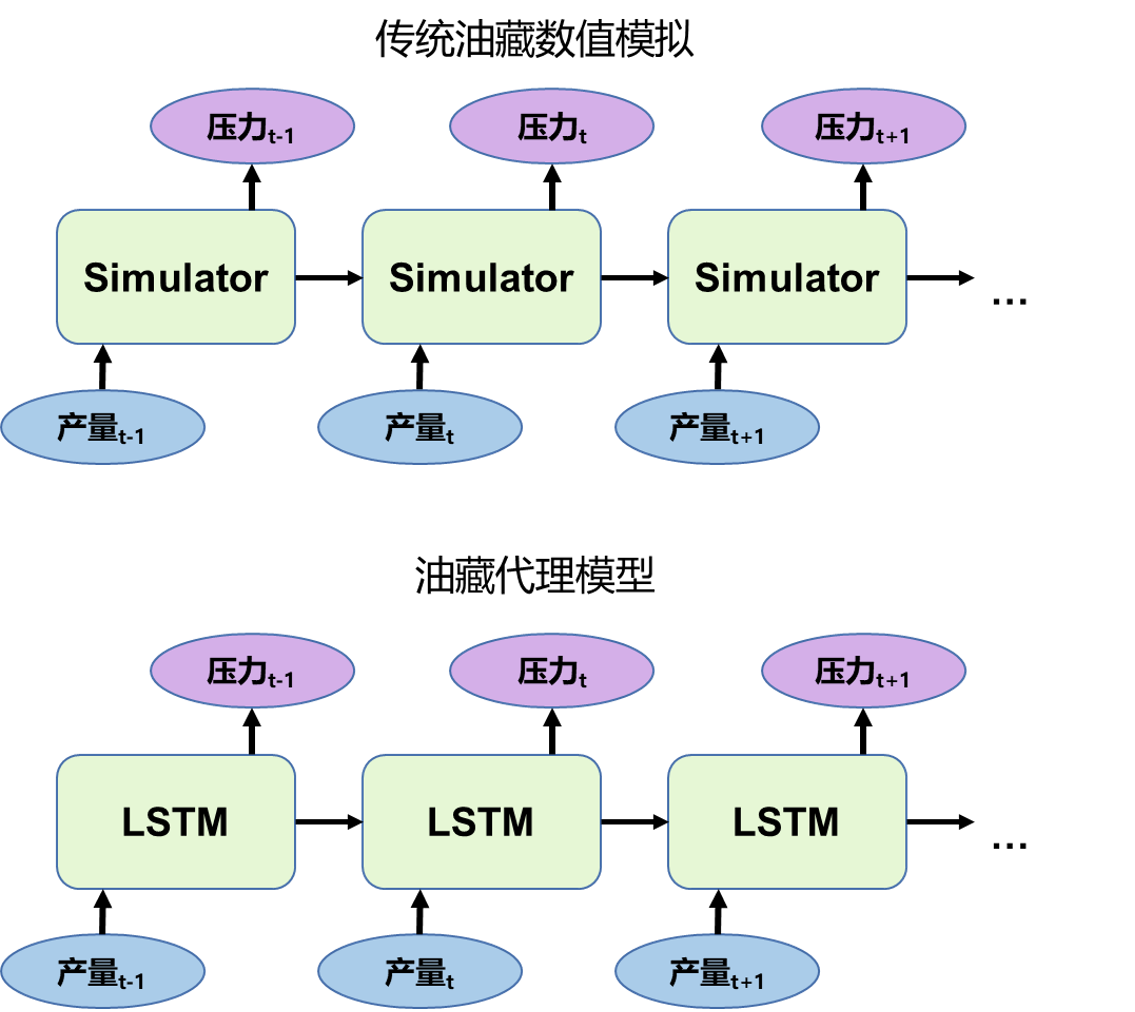
该深度学习的网络详细结构可参考网址进一步了解:视频教程。因此可以从图2中看出,传统的油藏模拟当输入为产量计算压力时,需要利用数值求解器对渗流方程进行离散化、线性化和迭代求解,这个过程非常耗时,尤其是当油藏模型较大时,计算一个时间步会耗时更久。而代理模型则不同,输入产量计算压力时,输入的产量则可以通过LSTM神经元快速计算压力,因为LSTM神经元内部都是简单的加减乘除公式,计算机几秒就可以完成。然而每个LSTM神经元的神经网络参数需要训练,因此需要大量的训练集来完成。
图2 传统油藏数值模拟与代理模型对比
以某个小油藏算例为例,原始模型定产量40m3/d,中途的产量的没有变化。然而我们想知道当产量波动变化时,油井的压力是如何波动的,此时我们可以构建N多个算例,每个算例在M个时间步上的产量进行扰动,因此可以观测压力波动的变化规律。但这种规律太过于复杂,只能让深度学习来完成,因此我们构建以LSTM网络的代理模型,在给定波动产量的情况下,快速预测出油井的压力是如何变化的。
图3 单井模型
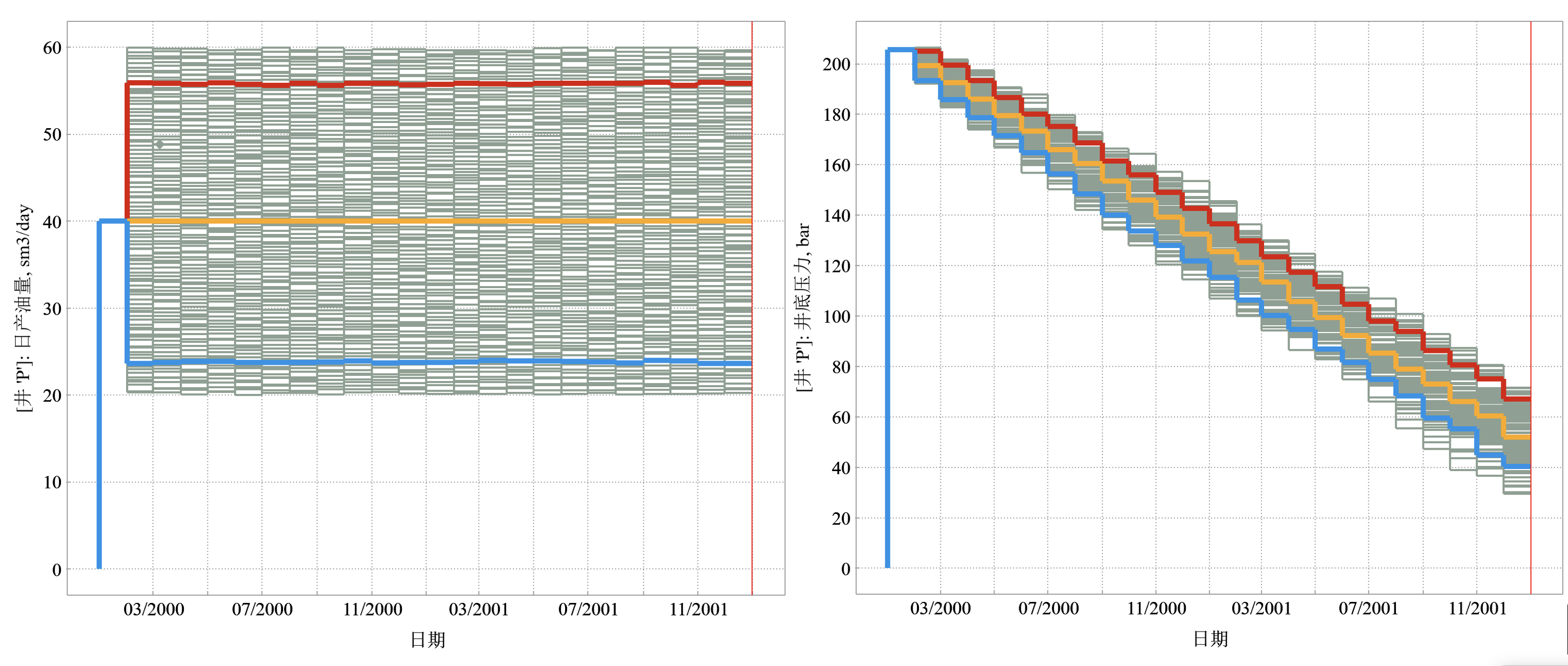
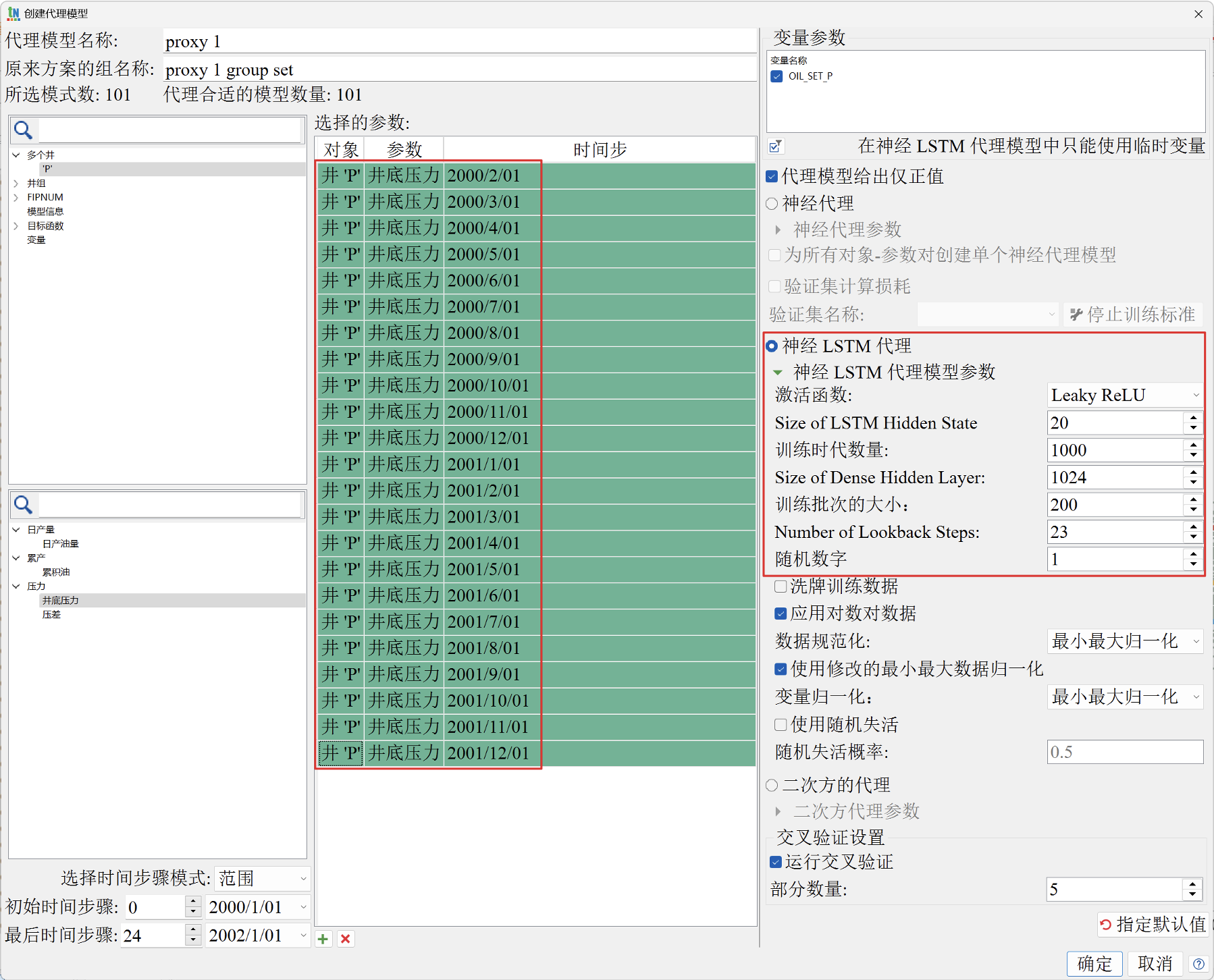
图4展示了我们通过扰动井的产量,计算了500组井压力递减的情况。其中红色、黄色和蓝色线分别为P90、P50和P10的概率分布线。产量的扰动可以利用拉丁超立方、蒙特卡洛等随机实验方法。图5展示了tNavigator软件的代理模型构建窗口,属于AHM模块,用500组算例进行深度学习训练,可以快速构建单井产量—>压力的映射关系,从而在给定产量的情况下,快速预测压力。其中可以自行调整LSTM网络模型的参数,包括激活函数、隐藏层、训练批次和数据归一化方法等。
图5 构建代理模型示意图
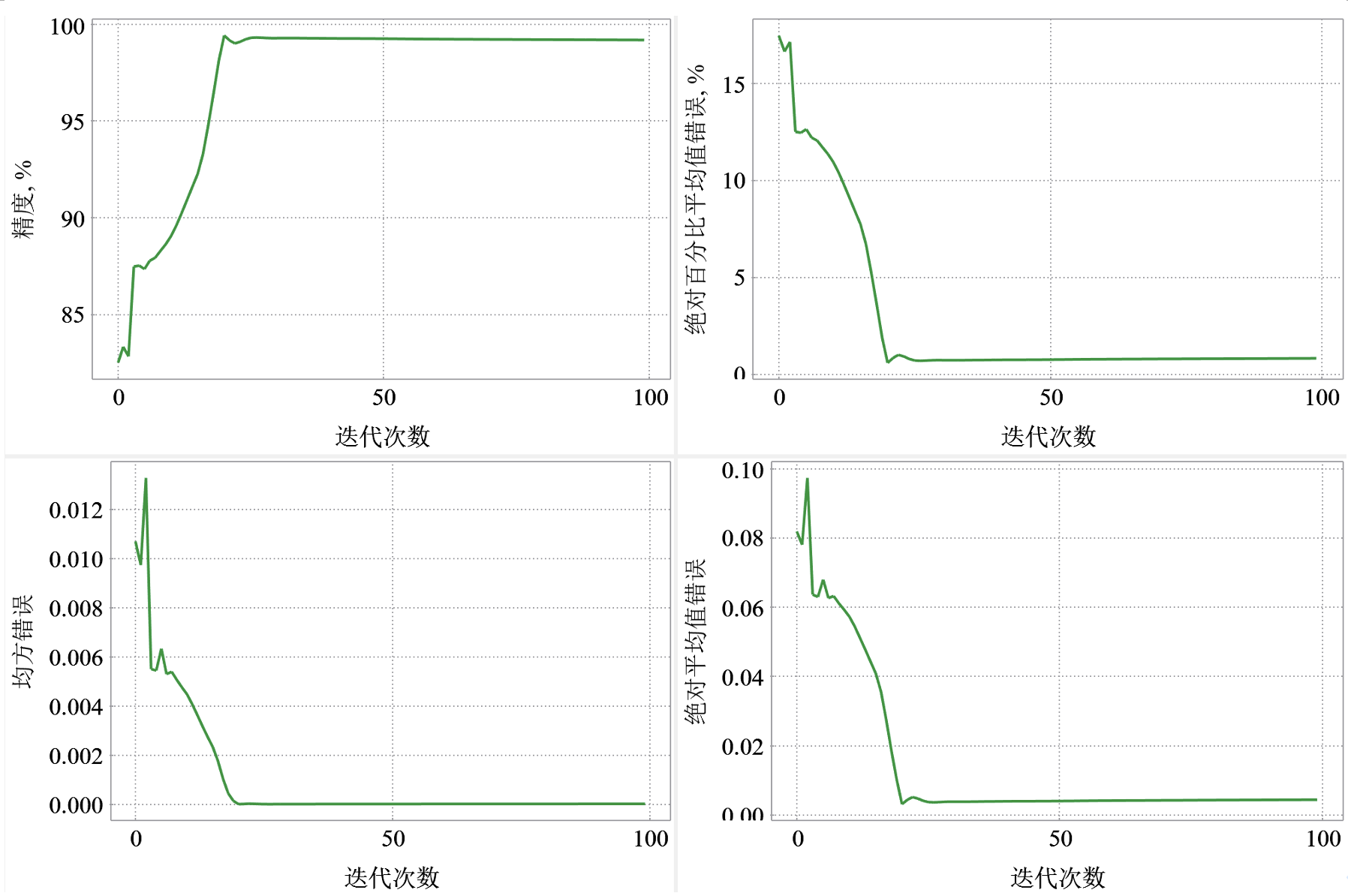
图6 代理模型训练结果
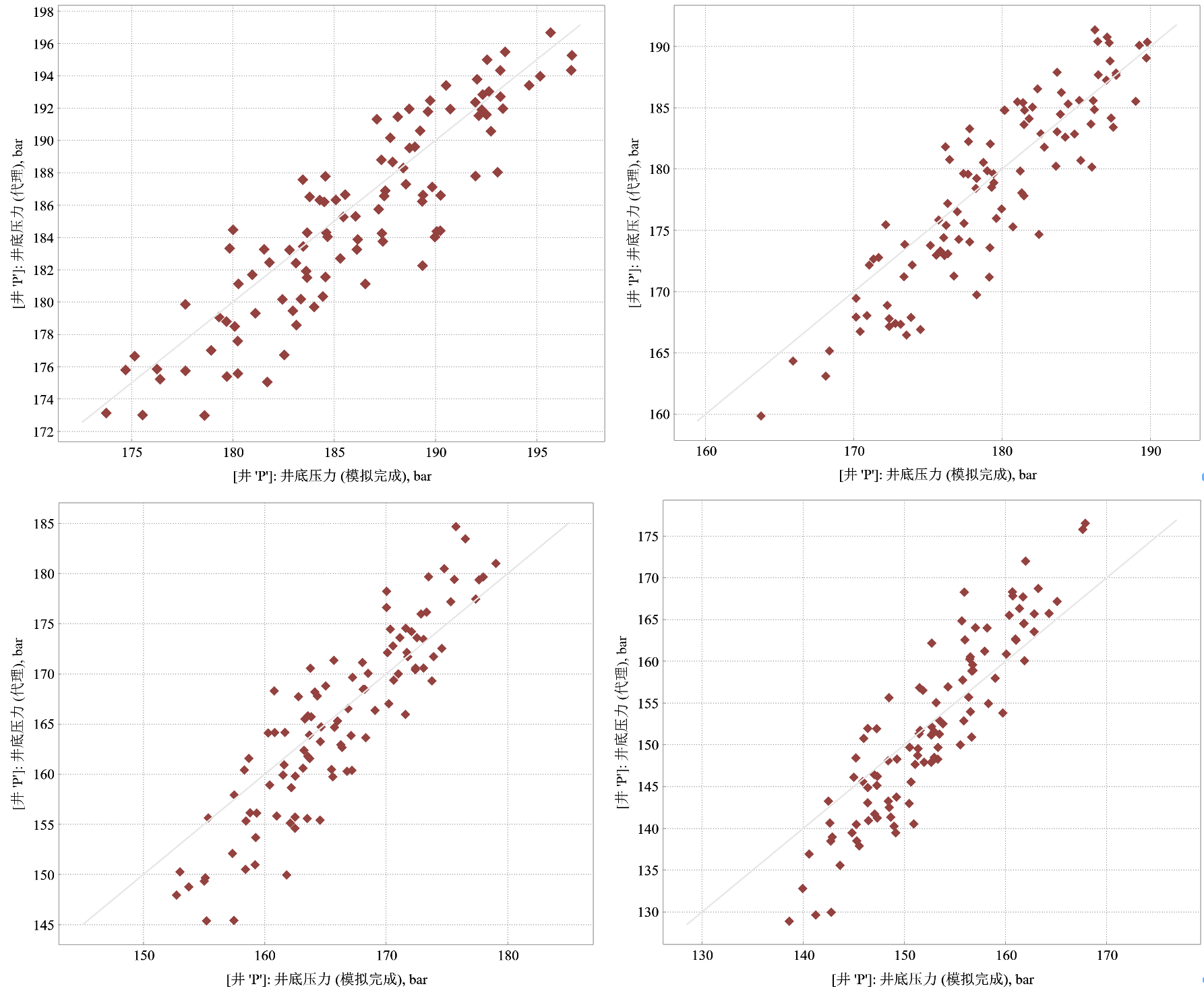
训练批次设置为100次,可以从图6中看出代理模型训练完成的精度,大约在20epoch之后,精度没有变化,最后的精度大约在96.8%左右。图7展示了部分时间步下,模拟的井底压力与代理模型计算的井底压力对比,从图中可以看出,散点基本分布在45°线附近,模型精度较好。读者可以尝试利用更多的训练集,比如1000组及以上的数模结果进行训练。